
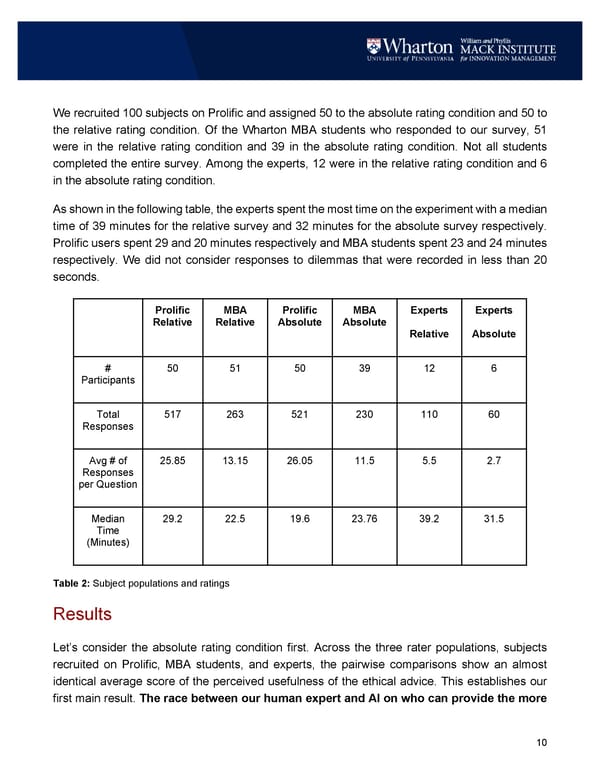
10 We recruited 100 subjects on Prolific and assigned 50 to the absolute rating condition and 50 to the relative rating condition. Of the Wharton MBA students who responded to our survey, 51 were in the relative rating condition and 39 in the absolute rating condition. Not all students completed the entire survey. Among the experts, 12 were in the relative rating condition and 6 in the absolute rating condition. As shown in the following table, the experts spent the most time on the experiment with a median time of 39 minutes for the relative survey and 32 minutes for the absolute survey respectively. Prolific users spent 29 and 20 minutes respectively and MBA students spent 23 and 24 minutes respectively. We did not consider responses to dilemmas that were recorded in less than 20 seconds. Prolific Relative MBA Relative Prolific Absolute MBA Absolute Experts Relative Experts Absolute # Participants 50 51 50 39 12 6 Total Responses 517 263 521 230 110 60 Avg # of Responses per Question 25.85 13.15 26.05 11.5 5.5 2.7 Median Time (Minutes) 29.2 22.5 19.6 23.76 39.2 31.5 Table 2: Subject populations and ratings Results Let’s consider the absolute rating condition first. Across the three rater populations, subjects recruited on Prolific, MBA students, and experts, the pairwise comparisons show an almost identical average score of the perceived usefulness of the ethical advice. This establishes our first main result. The race between our human expert and AI on who can provide the more
 Can AI Provide Ethical Advice? Page 9 Page 11
Can AI Provide Ethical Advice? Page 9 Page 11